
问题描述
在搭建 Kubernetes 集群过程中,安装了 kube-dns 插件后,运行一个 ubuntu 容器,发现容器内无法解析集群外域名,一开始可以解析集群内域名,一段时间后也无法解析集群内域名。
$ nslookup kubernetes.default
Server: 10.99.0.2
Address 1: 10.99.0.2 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'kubernetes.default'
排查过程
在排查问题前,先思考一下 Kubernetes 集群中的 DNS 解析过程,在安装好 kube-dns 的集群中,普通 Pod 的 dnsPolicy 属性是默认值 ClusterFirst,也就是会指向集群内部的 DNS 服务器,kube-dns 负责解析集群内部的域名,kube-dns Pod 的 dnsPolicy 值是 Default,意思是从所在 Node 继承 DNS 服务器,对于无法解析的外部域名,kube-dns 会继续向集群外部的 dns 进行查询,过程如图。
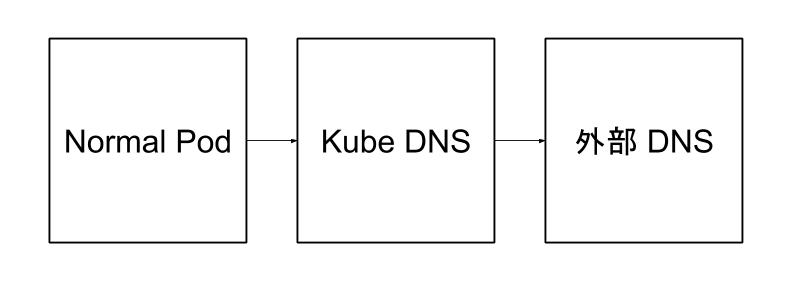
Ubuntu 容器是一个普通的 Pod,在 Linux 系统中,/etc/resolv.conf 是存储 DNS 服务器的文件,普通 Pod 的/etc/resolv.conf 文件应该存储的是 kube-dns 的 Service IP。
nameserver 10.99.0.2 # 这里存储的是kube-dns的Service IP
search default.svc.cluster.local. svc.cluster.local. cluster.local.
options ndots:5
查看后发现/etc/resolv.conf 文件中存储的是 kube-dns 的 Service IP,证明这一步没有问题,接下来查看一下 kube-dns 的 Pod,先进入 kube-dns 的 Pod 中检查一下/etc/resolv.conf 文件,这里存储的应该是集群外部的 DNS 服务器地址,查看后发现,这里存储的地址是 127.0.0.53,进一步查看 kube-dns Pod 的 log,发现出现了非常多的 i/o timeout 错误。
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:38019->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:57567->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:52599->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:42539->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:46885->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:44189->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:56505->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:47320->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:42464->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:49203->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:58103->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:47148->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:36883->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:40968->127.0.0.53:53: i/o timeout
2018/07/11 07:12:47 [ERROR] 2 [www.baidu.com](http://www.baidu.com/). A: unreachable backend: read udp 127.0.0.1:55672->127.0.0.53:53: i/o timeout
现在基本上可以发现问题的原因了,kube-dns 只能解析集群内部地址,而集群外部地址应该发给外部 DNS 服务器进行解析,由于 kube-dns Pod 中的/etc/resolv.conf 文件存储的 DNS 服务器地址是 127.0.0.53,127...*都是回环地址,也就是集群外域名的 DNS 解析请求会再次发送回 kube-dns,导致形成一个循环,这也是一秒钟会出现几十次 i/o timeout 日志的原因,请求会不断的在 kube-dns 中循环,kube-dns 就像一个黑洞一样,吃掉了所有 dns 解析请求,不断累积的请求最终会导致整个集群的网络出现卡顿。
为什么
虽然问题的原因找到了,但是为什么 kube-dns Pod 中/etc/resolv.conf 文件存储的 DNS 服务器是 127.0.0.53?
kube-dns Pod 的 dnsPolicy 值是 Default,查看一下 Kubernetes 文档。
“
Default”: The Pod inherits the name resolution configuration from the node that the pods run on. See related discussion for more details.
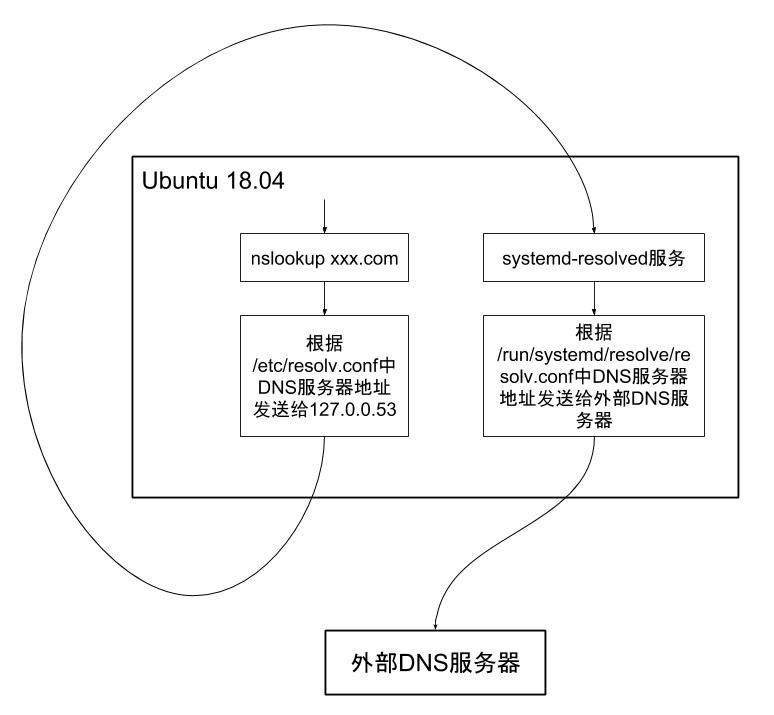
所以 kube-dns 的/etc/resolv.conf 文件是从 Node 中继承来的,查看 Node 中的/etc/resolv.conf 文件,存储的 DNS 服务器地址确实是 127.0.0.53,那么下一个问题出现了,在 Node 中发送 DNS 解析请求为什么不会产生回环的问题呢?
Node 使用的是 Ubuntu 18.04 Server,在这个版本的系统中,DNS 解析请求并不是直接发给所在网络的 DNS 服务器的,Ubuntu 18.04 中有一个 systemd-resolved 服务,为本地应用程序提供了 DNS 解析服务,例如 nslookup localhost,解析程序从/etc/resolv.conf 文件中找到 DNS 服务器 127.0.0.53,发送解析请求,systemd-resolved 会监听在 53 端口上,捕获到解析请求后,如果是自己可以解析的,例如 localhost,会直接返回 127.0.0.1,如果不能解析,才会发送给外部服务器,而外部服务器的地址存储在/run/systemd/resolve/resolv.conf 文件中,这个文件是 systemd-resolved 服务器的配置文件,过程如图。
怎么破
理解了问题的来龙去脉,解决问题的办法也就应运而生。在 Kubernetes 集群中,kubelet 是 worker 组建,负责管理 Pod,根据 kubernetes 文档,kubelet 默认会从 Node 的/etc/resolv.conf 文件读取 DNS 服务器地址,使得 dnsPolicy 是 Default 的 Pod 得以继承,kubelet 中的–resolv-conf 参数可以指定这个配置文件的地址。在 Ubuntu 18.04 中,将这个参数设置为 systemd-resolved 的 DNS 服务器配置文件/run/systemd/resolve/resolv.conf,Pod 就会继承真正的外部 DNS 服务器。
总结
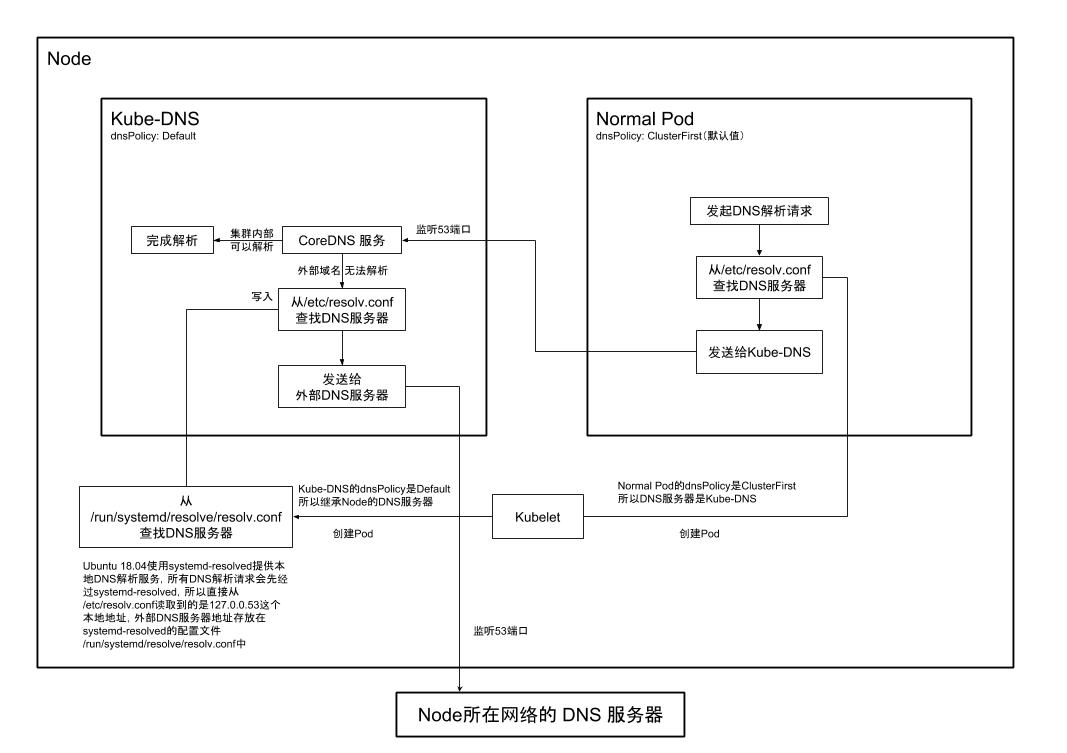
通过对问题的探究,也理解了 Kubernetes 集群中 DNS 解析的完整过程,如图。
* 在 Ubuntu 16.04 中也是类似的逻辑,只不过 systemd-resolved 换成了 dnsmasq,监听地址是 127.0.1.1 * 在具体实践过程中,也顺便探究了 CoreDNS 和 KubeDNS 架构和解析逻辑上的区别,不过不在此问题的讨论范围,有兴趣的朋友可以自己看一下。 * 如果 Kubernetes 集群是安装在 NAT 网络下的虚拟机上,虚拟机(也就是 Kubernetes 集群中的 Node)中/etc/resolv.conf 文件可能被修改为 NAT 的地址,也就不会出现上面这个问题。
参考内容
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/ https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/ https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/ https://www.freedesktop.org/software/systemd/man/systemd-resolved.service.html https://github.com/kubernetes/kubernetes/issues/49411 https://github.com/kubernetes/kubernetes/issues/45828