在 macOS 上使用 Bob 划词翻译时,最头疼的往往是各种翻译 API 的额度与网络问题:DeepL 免费额度少且易被风控,OpenAI API 容易断连且需要持续付费,传统的机器翻译虽然免费但翻译效果差。
今天分享一个完全免费、零延迟、隐私性极高,且翻译质量直逼专业水平的终极方案:Bob + Ollama + TranslateGemma。通过在本地运行 Google 专门为翻译任务优化的 TranslateGemma 模型,实现真正的“翻译自由”。
1. 核心优势:为什么是 TranslateGemma?
在介绍具体步骤前,先简单说明一下为什么这个组合是目前 macOS 翻译方案的“天花板”:
- Google 官方翻译微调:TranslateGemma 是 Google 专门针对翻译任务微调的 Gemma 模型,支持 55 种语言互译。相比通用的 LLM,它在多语种翻译的准确性和信达雅程度上表现更出色。
- 完全免费 & 离线运行:模型运行在本地,不依赖任何第三方 API,不消耗流量,且完全不用担心隐私泄露(特别适合翻译公司敏感文档)。
- 极速响应:Ollama 完美适配 Apple Silicon (M1/M2/M3/M4) 的 Metal 架构,推理速度极快,体验上快于调用 Gemini 或 ChatGPT API。
- 生态成熟:配合 Bob 这款 macOS 最强翻译聚合工具,可以无缝融入日常工作流(划词、截图、输入框翻译)。
2. 准备工作
在开始之前,请确保你已经安装了以下软件:
- Ollama: https://ollama.com/ (用于运行本地大模型)
- Bob: https://bobtranslate.com/ (macOS 上的老牌翻译软件)
- 硬件建议: 建议使用 M1 芯片及以上的 Mac 设备。8GB 内存推荐使用 4b 量化版本,16GB 及以上可以尝试更高精度的模型。
3. 部署 TranslateGemma 模型
安装好 Ollama 后,我们需要拉取 Google 的翻译模型 TranslateGemma。
打开终端 (Terminal)。
运行以下命令拉取并运行模型:
ollama run translategemma:4b小贴士:
translategemma:4b是 40 亿参数的版本,在速度和质量之间取得了很好的平衡,适合大多数用户。- 如果你追求极致效果且内存充足 (16GB+),可以尝试更大的
12b或27b版本。
当看到
>>>提示符时,说明模型已成功加载。你可以试着输入一句英文看看翻译效果。测试完毕后,按Ctrl + D退出即可,模型会在后台随时待命。
4. 配置 Bob 使用 Ollama 服务
接下来我们将本地模型接入 Bob。
打开 Bob 的 设置。
点击左侧导航栏的 服务。
点击右下角的 + 号,选择 Ollama 服务添加。
进行如下关键配置:
- 名称:
TranslateGemma(方便识别) - 服务地址: 保持默认
http://127.0.0.1:11434即可。 - 模型名称: 填入
translategemma:4b(必须与你在终端下载的模型名一致)。 - Prompt (提示词): 留空!
由于 TranslateGemma 是专门的翻译模型,与通用对话模型不同,它不需要自定义 Prompt。直接输入待翻译文本即可获得最佳效果。
- 名称:
点击“保存”。
5. 实际使用效果与进阶玩法
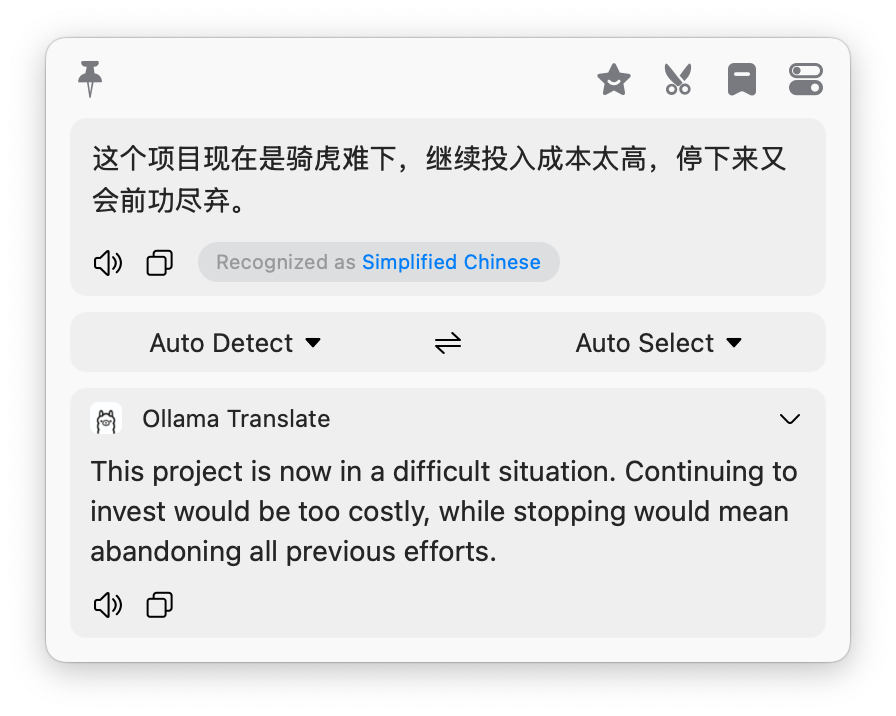
现在,选中一段文字,按下 Bob 的快捷键,你就会发现翻译结果秒出。
对比优势:
- 无需微调语气:它天生就是为了翻译存在的,不会像 ChatGPT 那样偶尔罗嗦或者解释一堆。
- 长难句处理:得益于 Gemma 的上下文理解能力,它对科技文献、长难句的断句和重组能力远超传统机翻。
进阶玩法:多服务分流
虽然 TranslateGemma 不需要 Prompt,但你仍然可以利用 Bob 的多服务功能配置不同的场景。
比如,你可以添加另一个通用模型(如 llama3 或 qwen)专门用于“润色”或“解释单词”,与 TranslateGemma 的“纯翻译”功能互补。
6. 总结
通过 Ollama + TranslateGemma,我们不仅彻底摆脱了 API 的付费焦虑,更在 macOS 上拥有了一个隐私安全、离线可用、质量顶尖的私人翻译官。
如果你是经常需要阅读外文文献的科研人员、开发者或学生,强烈建议花 5 分钟部署这套方案。这可能是目前 macOS 上最优雅、最高效的免费翻译解决方案。