
In a Python Web application deployed on Kubernetes and running with Gunicorn, a series of errors occurred when uploading large files. Here, I document the solution approach.
File Upload Process
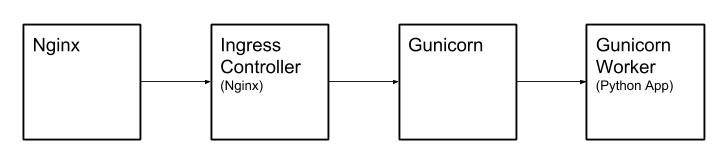
File upload flow:
- The uploaded file first reaches the host machine where Kubernetes is running.
- Nginx on the host machine forwards it via Proxy to the Ingress Controller in the Kubernetes cluster, which is also implemented using Nginx.
- Nginx in the Ingress Controller forwards it via Proxy to Gunicorn.
- Gunicorn starts several Workers to handle requests, so it forwards the request to a Worker.
- The Worker is the final Python Web App.
Solving Error 413
The first encountered error was 413 Request Entity Too Large. During the upload process, the connection was interrupted (almost always at the same upload percentage), and the request returned 413. Initially, I considered the possibility of Nginx having a request body size limit. Checking the Nginx documentation, I found that the client_max_body_size parameter controls the request body size, with a default setting of 1mb.
client_max_body_size: Sets the maximum allowed size of the client request body, specified in the “Content-Length” request header field. If the size in a request exceeds the configured value, the 413 (Request Entity Too Large) error is returned to the client. Please be aware that browsers cannot correctly display this error. Setting size to 0 disables checking of client request body size.
First, add the following configuration to the http domain of Nginx on the Kubernetes host machine.
client_max_body_size 1024m;
Note that, besides the Nginx running on the Kubernetes host machine, you also need to modify the Nginx in the Ingress Controller. The modification method for Ingress Nginx is to add the following configuration in the Annotation field.
"nginx.ingress.kubernetes.io/proxy-body-size": "1024m"
Solving Error 504
Upon retrying the upload, the interface still returned an error, this time a 504 Gateway Timeout. Checking the request in Chrome’s developer tools, I found that the upload took at least 5 minutes. Next, I focused on Nginx’s timeout mechanism.
I increased the read and write timeout limits in both Nginx and Ingress, setting the send timeout to 600s and the read timeout to 30s.
proxy_send_timeout 600s;
proxy_read_timeout 30s;
After another attempt, the same 504 error occurred. Could there be other timeout fields that need setting? Further documentation review revealed a clue.
proxy_send_timeout: Sets a timeout for transmitting a request to the proxied server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the proxied server does not receive anything within this time, the connection is closed.
proxy_read_timeout: Defines a timeout for reading a response from the proxied server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the proxied server does not transmit anything within this time, the connection is closed.
The send and read here refer to Nginx itself, not the client. The timeout occurs when Nginx sends the file to the Upstream, and when the Upstream finishes processing and returns, it exceeds the proxy_read_timeout limit. Therefore, the read_timeout needs to be increased.
Configure the Nginx on the host machine and Ingress as follows.
proxy_send_timeout 30s;
proxy_read_timeout 600s;
nginx.ingress.kubernetes.io/proxy-send-timeout: 30s
nginx.ingress.kubernetes.io/proxy-read-timeout: 600s
Solving Error 502
After adjusting the timeout and file upload size limits, a new error 502 Bad Gateway appeared. This time, there was no clue. Since it’s a new error, the previous adjustments should be effective, and it’s not caused by the previous two limits. By checking the logs of Nginx and Ingress, I found the following error in Ingress.
2019/02/27 07:18:36 [error] 4265#4265: *19932411 upstream prematurely closed connection while reading response header from upstream, client: 172.20.0.1, server: example.com, request: "POST /upload HTTP/1.0", upstream: "http://172.0.0.1/upload", host: "example.com", referrer: "http://example.com/"
This is quite strange. I already adjusted the timeout, so why is there still a timeout error in Ingress? From the logs, it seems the Upstream in Ingress timed out, which is Gunicorn. Someone on Stackoverflow encountered a similar issue, and the answer was to set the -t parameter for Gunicorn. Checking Gunicorn’s documentation, the timeout parameter is defined as follows.
timeout: Workers silent for more than this many seconds are killed and restarted. Generally set to thirty seconds. Only set this noticeably higher if you’re sure of the repercussions for sync workers. For the non sync workers it just means that the worker process is still communicating and is not tied to the length of time required to handle a single request.
This means that when a Worker processes a file upload request, if it doesn’t respond to the Master within the default timeout, it will be killed. This explains why the connection is closed when Ingress retrieves the return value from Upstream. Modify Gunicorn’s configuration to set the timeout to 600s, retry the upload, and the issue is resolved.