
When transmitting data over a network, to prevent network congestion, it’s necessary to limit the outgoing traffic so that data is sent out at a relatively uniform speed. The token bucket algorithm achieves this functionality by controlling the number of data packets sent to the network and allowing for burst data transmission.
What is a Token?
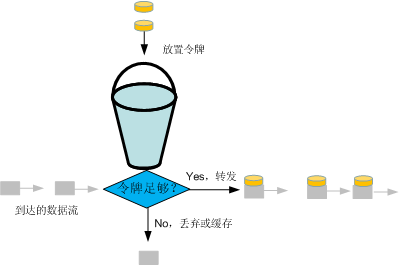
From the name “token bucket,” it seems to be a bucket filled with tokens. So, what exactly is a token?
Think of the command token held by a character in a historical drama, which allows them to issue commands and enforce rules. In the world of computers, a token also signifies permission to perform operations. With a token, you are authorized to proceed; without it, nothing can be done.
Using Tokens to Implement a Rate Limiter
We use 1 token to represent the qualification to send 1 byte of data. Suppose we continuously issue tokens to a program, the program then has the qualification to continuously send data. If we stop issuing tokens, the program is throttled and cannot send data. Let’s discuss the rate limiter, which allows a program to send only a certain amount of data within a unit of time. Suppose we issue 10 tokens per second, then the program’s data sending speed is limited to 10 bytes/s. If more than 10 bytes of data need to be sent in one second, they will be discarded due to a lack of tokens.
Improving the Rate Limiter—Adding a Bucket

Our implemented rate limiter has a constant speed, but in real applications, there are often burst transmission demands (requiring faster sending but not lasting long enough to cause network congestion). Such data would be blocked by our rate limiter due to a lack of tokens.
To modify the rate limiter, we still generate 10 tokens per second, but we store the generated tokens in a bucket. When the program needs to send data, it takes tokens from the bucket. If not needed, tokens accumulate in the bucket. Suppose 10 tokens accumulate in the bucket, the program can send up to 20 bytes of data in one second, meeting burst transmission requirements. Since the tokens in the bucket are used up, the next second still allows only 10 bytes of data to be sent, preventing network strain from continuous large data transmission.
Implementing the Token Bucket in 15 Lines of Python Code
The token bucket needs to generate tokens at a certain rate and store them in the bucket. When the program wants to send data, it retrieves tokens from the bucket. There seems to be a problem here: if we use an infinite loop to continuously issue tokens, the program gets blocked. Is there a better way?
We can calculate the number of tokens available in the bucket by subtracting the last token retrieval time from the current time and multiplying by the token issuance rate. This avoids the logic of continuous token issuance.
Now, let’s look at the code:
import time
class TokenBucket(object):
# rate is the token issuance rate, capacity is the bucket size
def __init__(self, rate, capacity):
self._rate = rate
self._capacity = capacity
self._current_amount = 0
self._last_consume_time = int(time.time())
# token_amount is the number of tokens needed to send data
def consume(self, token_amount):
increment = (int(time.time()) - self._last_consume_time) * self._rate # Calculate new tokens issued since the last send
self._current_amount = min(
increment + self._current_amount, self._capacity) # Token count cannot exceed bucket capacity
if token_amount > self._current_amount: # If there aren't enough tokens, data cannot be sent
return False
self._last_consume_time = int(time.time())
self._current_amount -= token_amount
return True