asyncio was introduced in Python 3.4 as part of the standard library, adding support for asynchronous I/O. Based on an event loop, asyncio allows for easy implementation of asynchronous I/O operations. Next, we’ll use libraries based on asyncio to create a high-performance crawler.
Preparation
Earth View from Google Earth is a Chrome extension that automatically loads a background image from Google Earth when a new tab is opened.
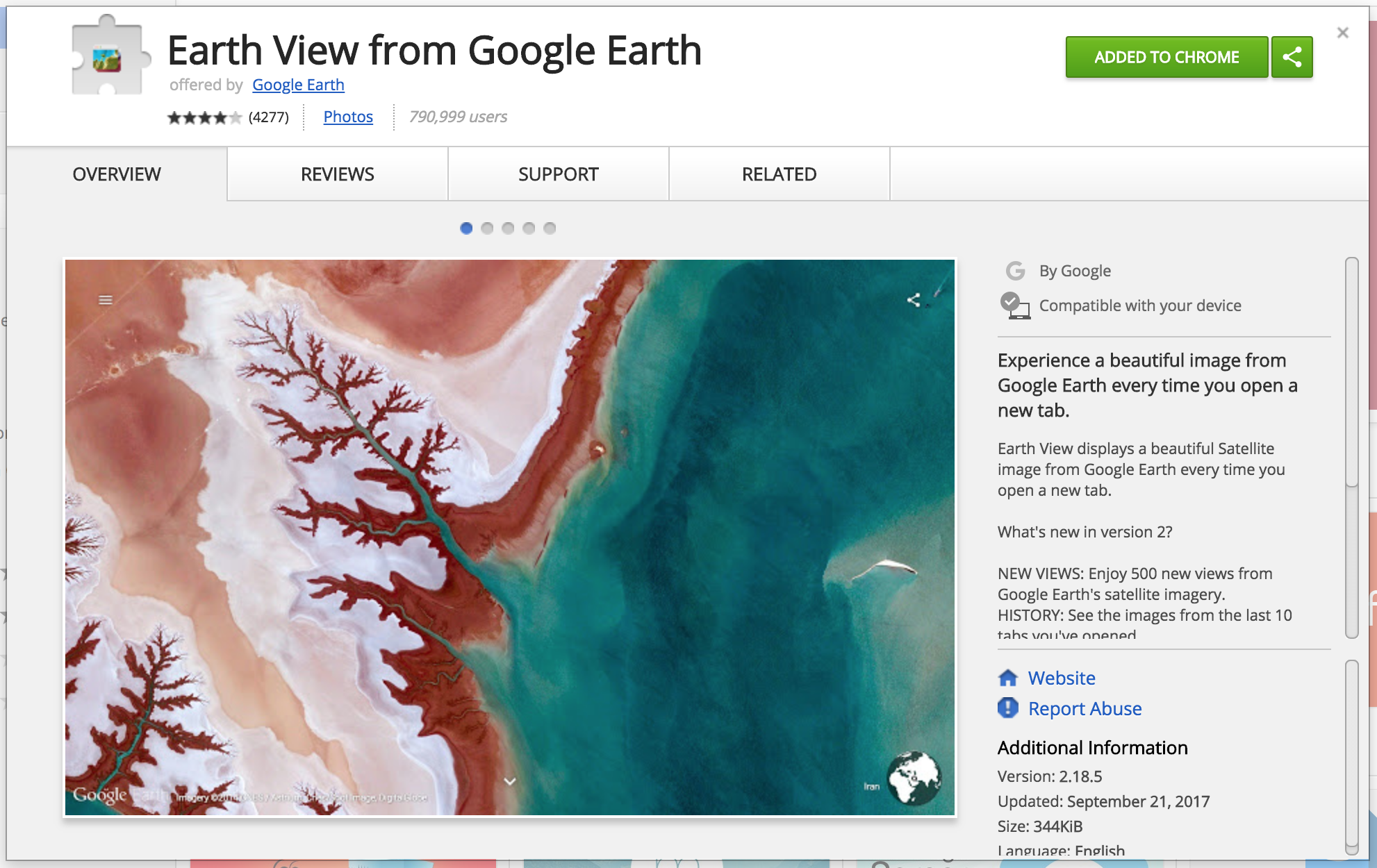
Using Chrome’s developer tools to observe the network requests of the extension, we find that it requests a JSON file from an address like https://www.gstatic.com/prettyearth/assets/data/v2/1234.json. This file contains Base64-encoded image content. We observed that the image IDs range roughly from 1000 to 8000, and our crawler will fetch these beautiful background images.
Implementing the Main Logic
Since the target is a JSON file, the main logic of the crawler becomes fetch JSON –> extract image –> save image.
requests is a commonly used HTTP request library, but since requests are synchronous, we will use aiohttp, an asynchronous HTTP request library, instead.
async def fetch_image_by_id(item_id):
url = f'https://www.gstatic.com/prettyearth/assets/data/v2/{item_id}.json'
# Since the URL is https, choose not to verify SSL
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(verify_ssl=False)) as session:
async with session.get(url) as response:
# After fetching, convert the JSON string to an object
try:
json_obj = json.loads(await response.text())
except json.decoder.JSONDecodeError as e:
print(f'Download failed - {item_id}.jpg')
return
# Extract the image content field from JSON, decode it from Base64 to binary content
image_str = json_obj['dataUri'].replace('data:image/jpeg;base64,', '')
image_data = base64.b64decode(image_str)
save_folder = dir_path = os.path.dirname(
os.path.realpath(__file__)) + '/google_earth/'
with open(f'{save_folder}{item_id}.jpg', 'wb') as f:
f.write(image_data)
print(f'Download complete - {item_id}.jpg')
aiohttp is based on asyncio, so you need to use the async/await syntax sugar when calling it. As shown, since aiohttp provides a ClientSession context, the code uses the async with syntax sugar.
Adding Parallel Logic
The above code is for fetching a single image. To fetch images in bulk, we need to nest another method:
async def fetch_all_images():
# Use Semaphore to limit the maximum concurrency
sem = asyncio.Semaphore(10)
ids = [id for id in range(1000, 8000)]
for current_id in ids:
async with sem:
await fetch_image_by_id(current_id)
Next, add this method to asyncio’s event loop.
event_loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_all_images())
results = event_loop.run_until_complete(future)
Accelerating with uvloop
uvloop is based on libuv, a high-performance asynchronous I/O library implemented in C. uvloop can replace asyncio’s default event loop, further speeding up asynchronous I/O operations.
Using uvloop is straightforward; before obtaining the event loop, call the following method to set asyncio’s event loop policy to uvloop’s event loop policy.
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
Using the above code, we can quickly fetch approximately 1500 images.
Performance Comparison
To verify the performance of aiohttp and uvloop, I implemented a multi-process version of the crawler using the requests+concurrent library. The time taken to fetch 20 IDs is shown below.
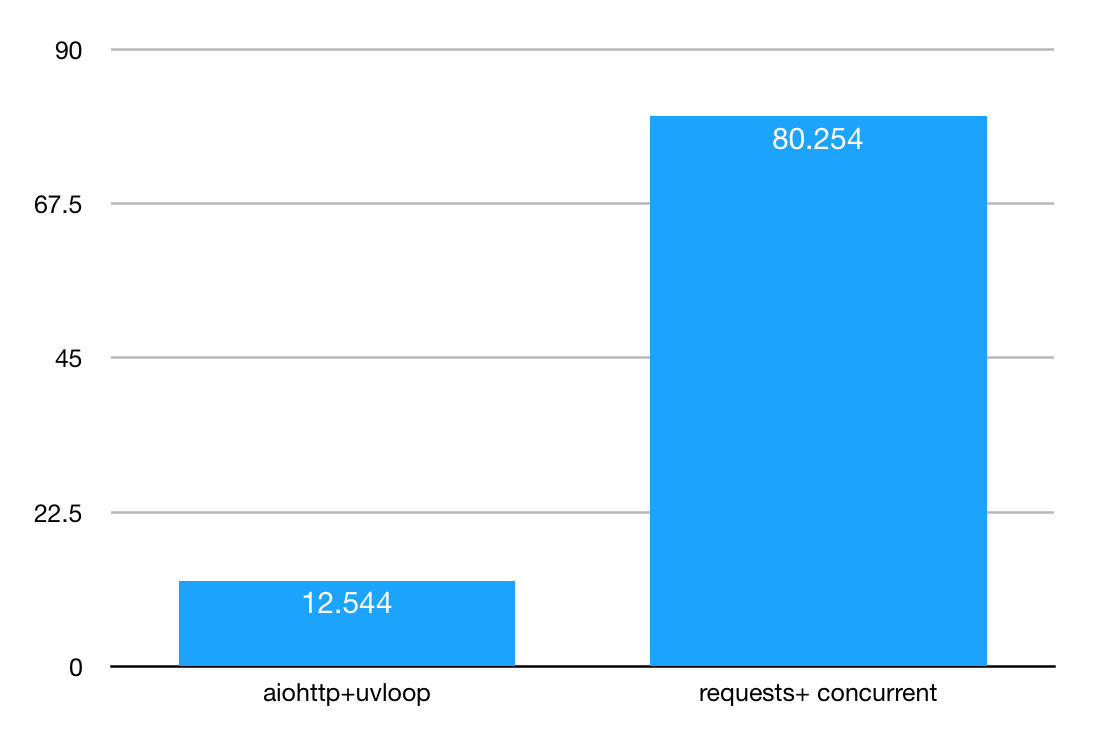
As you can see, the time difference is about 7 times, with the aiohttp+uvloop combination having an overwhelming advantage in I/O-intensive scenarios like web crawling. I believe that in the near future, libraries based on asyncio will save countless web crawling engineers from overtime work.